[Java] 47. JPA의 Entity 클래스의 레퍼런스 설정(cascade, fetch)
안녕하세요. 명월입니다.
이 글은 JPA의 Entity 클래스의 레퍼런스 설정(cascade, fetch)에 대한 글입니다.
이전 글에서 IDE툴(eclipse)에서 JPA의 Entity를 자동 생성해서 기본적으로 다시 설정해야 하는 방법을 소개했습니다.
링크 - [Java] 46. JPA의 Entity 클래스의 기본 설정(@GeneratedValue, @ManyToMany)
기본적인 설정으로는 프로젝트에서 사용하는데 문제가 없습니다만, 성능을 위해서 좀 더 수정해야 할 것이 있습니다.
예를 들면 이전 테이블에서 user 테이블을 검색해서 info 테이블의 데이터를 가져오는데 기본적인 설정으로는 user의 하위 info 데이터가 없습니다.
import java.util.List;
import java.util.Optional;
import javax.persistence.EntityManager;
import javax.persistence.EntityManagerFactory;
import javax.persistence.EntityTransaction;
import javax.persistence.Persistence;
import model.User;
import model.Info;
public class Main {
// 람다식 인터페이스
interface Expression {
void run(EntityManager em);
}
// Persistence로 EntityManager를 가져와서 실행하고 종료하는 함수
private static void transaction(Expression lambda) {
// FactoryManager를 생성합니다. "JpaExample"은 persistence.xml에 쓰여 있는 이름이다.
EntityManagerFactory emf = Persistence.createEntityManagerFactory("JpaExample");
// Manager를 생성한다.
EntityManager em = emf.createEntityManager();
try {
// transaction을 가져온다.
EntityTransaction transaction = em.getTransaction();
try {
// transaction 실행
transaction.begin();
// 람다식을 실행한다.
lambda.run(em);
// transaction을 커밋한다.
transaction.commit();
} catch (Throwable e) {
// 에러가 발생하면 rollback한다.
if (transaction.isActive()) {
transaction.rollback();
}
// 에러 출력
e.printStackTrace();
}
} finally {
// 각 FactoryManager와 Manager를 닫는다.
em.close();
emf.close();
}
}
// 실행 함수
@SuppressWarnings("unchecked")
public static void main(String... args) {
transaction((em) -> {
// user 테이블로 부터 데이터 취득
List<User> users = em.createNamedQuery("User.findAll").getResultList();
// nowonbun 데이터 취득
User user = users.stream().filter(x -> "nowonbun".equals(x.getId())).findFirst().get();
// Stream 식의 경우 하위 레퍼런스를 읽어오지 않는다.
Optional<Info> info = user.getInfos().stream().findFirst();
// info 값이 비어 있는 가 확인
if(info.isEmpty()) {
// 콘솔 표시
System.out.println("Empty");
} else {
// 데이터가 있으면 콘솔 표시
System.out.println(info.get().getIdx());
}
// get(0)으로 하면 하위 레퍼런스를 읽어와서 idx를 출력한다.
System.out.println(user.getInfos().get(0).getIdx());
});
}
}
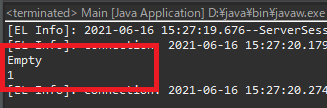
위 예제를 보시면 user클래스에서 getInfos()를 호출해서 stream식으로 데이터를 출력하면 데이터가 없는 것으로 나옵니다.
그러나 get(0)나 foreach를 사용하면 함수 호출과 동시에 하위 레퍼런스 데이터를 데이터베이스에서 검색해서 가져옵니다.
즉, 처음 user 클래스에는 데이터가 없었습니다만 get이나 iterator를 호출하면 그때 데이터를 데이터베이스로 가져오는 것입니다.
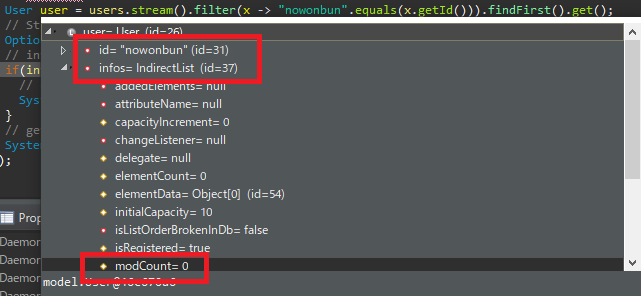
사양에 따라 stream식을 사용하지 않으면 상관이 없으나 최근의 프로그램 코드는 stream식을 사용하지 않으면 굉장히 복잡해지기 때문에 지금은 필수가 되었습니다.
이것을 해결하는 방법이 fetch 설정입니다.
fetch
fetch는 해당 클래스를 데이터베이스에서 검색해서 가져올 때, 동시에 가져올지 아니면 get을 사용할 때에 가져올지 결정하는 옵션입니다.
옵션의 종류는 EAGER와 LAZY이 있습니다. EAGER의 경우는 해당 클래스의 데이터를 가져올때 Join해서 가져오고 LAZY의 경우는 요청이 있을 때 가져오는 것입니다.
즉, 위 예제처럼 get이 요청이 있을 때는 LAZY의 옵션이고 따로 설정을 하지 않으면 디폴트 설정입니다.
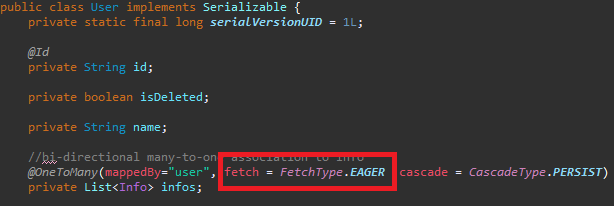
해당 변수에 fetch = FetchType.EAGER를 설정했습니다.

첫번째 예제를 다시 실행했더니 이번에는 콘솔 출력에 Empty가 아니고 데이터가 표시됩니다.
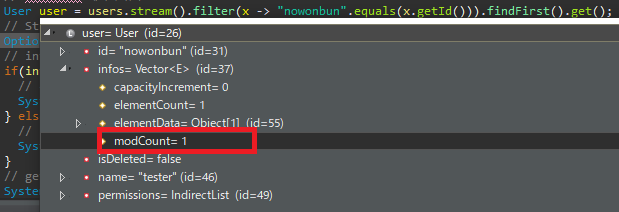
디버그로 찍어도 user를 가져오는 단계에서 이미 데이터가 있는 것을 확인할 수 있습니다.
이게 왜 옵션으로 선택을 할 수 있는 것이냐면 데이터 전략에 따라 달라집니다.
만약에 우리가 Master 테이블에서 연결되어 있는 Reference 데이터가 일만건, 십만건이라고 하면 그 데이터를 가져올 때, Join 데이터를 가져오는 것만으로 시간이 엄청 걸릴 것입니다.
생각보다 new로 클래스를 생성하는 것이 생각보다 시간이 많이 걸립니다. 그럴 때는 당연히 LAZY 설정으로 데이터를 가져오는 것을 별도로 해야 부담이 없습니다.
그러나 Transaction 테이블에서는 Reference 데이터가 Master의 경우라면, 사양 속에서 데이터 체크와 분기를 해야할 때 자주 사용하게 됩니다. 그럴 때마다 데이터베이스에 접속해서 데이터를 가져오는 커넥션이 많아지면 반대로 시스템이 느려집니다.
커넥션이라는 건 결국 Socket으로 리소스를 사용하는 것인데, IO와 마찬가지로 시스템 리소스라는 것은 매우 느립니다.
프로그램 설계도 이걸 매우 주의해 가면서 stream식보다는 foreach나 for를 이용해서 탐색, 검색하는 게 좋습니다.
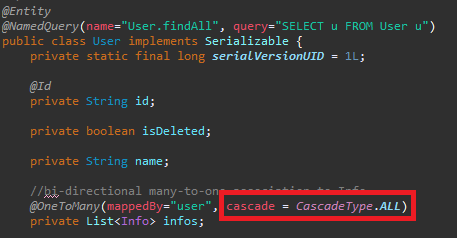
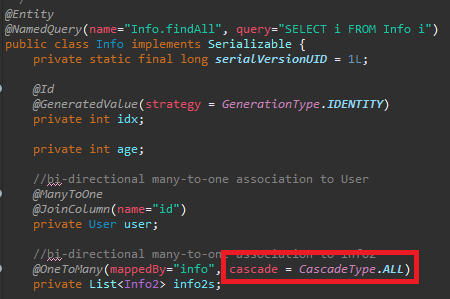
Cascade
Cascade란 데이터베이스에서 영속성 전이라는 데이터 일관성을 설정하는 옵션입니다.
예를 들면 Database에서 User의 데이터를 삭제를 하려면 연결된 info 데이터를 삭제해야 하고, info 데이터를 삭제하려면 연결된 info2 데이터를 삭제해야 합니다.
물론 이것이 프로그램에서 차례로 info2를 삭제하고 info를 삭제하고 user를 삭제하면 됩니다.
이렇게 할 경우 첫째, 소스가 매우 복잡해지고 관련 데이터베이스가 변경이 생길 때마다 소스를 다 수정해야 하는 문제가 있습니다. 이렇게 되면 우리가 JPA를 사용할 필요가 없겠지요.
둘째는 문제가 있는 부분이 만약에 info2를 삭제하고 info를 삭제하는 동작에서 에러가 발생했습니다. 그럴 경우 info2가 삭제가 되었기 때문에 rollback이 안됩니다. 이건 transaction의 문제이긴 합니다만 영속성과도 관계가 있습니다.
즉, 한번에 삭제가 되어야 합니다.
Cascade 옵션으로 설정할 수 있습니다.
import java.util.List;
import java.util.Optional;
import javax.persistence.EntityManager;
import javax.persistence.EntityManagerFactory;
import javax.persistence.EntityTransaction;
import javax.persistence.Persistence;
import model.User;
import model.Info;
public class Main {
// 람다식 인터페이스
interface Expression {
void run(EntityManager em);
}
// Persistence로 EntityManager를 가져와서 실행하고 종료하는 함수
private static void transaction(Expression lambda) {
// FactoryManager를 생성합니다. "JpaExample"은 persistence.xml에 쓰여 있는 이름이다.
EntityManagerFactory emf = Persistence.createEntityManagerFactory("JpaExample");
// Manager를 생성한다.
EntityManager em = emf.createEntityManager();
try {
// transaction을 가져온다.
EntityTransaction transaction = em.getTransaction();
try {
// transaction 실행
transaction.begin();
// 람다식을 실행한다.
lambda.run(em);
// transaction을 커밋한다.
transaction.commit();
} catch (Throwable e) {
// 에러가 발생하면 rollback한다.
if (transaction.isActive()) {
transaction.rollback();
}
// 에러 출력
e.printStackTrace();
}
} finally {
// 각 FactoryManager와 Manager를 닫는다.
em.close();
emf.close();
}
}
// 실행 함수
@SuppressWarnings("unchecked")
public static void main(String... args) {
transaction((em) -> {
// user 테이블로 부터 데이터 취득
List<User> users = em.createNamedQuery("User.findAll").getResultList();
// nowonbun 데이터 취득
User user = users.stream().filter(x -> "nowonbun".equals(x.getId())).findFirst().get();
// 데이터 삭제
em.remove(user);
});
}
}
위 예제는 user테이블에서 nowonbun를 검색해서 삭제하는 코드입니다. 따로 info테이블과 info2테이블은 검색도 하지도 않았는 데도 삭제가 되었고 실행되는데 에러가 발생하지 않았습니다.
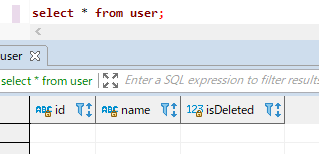
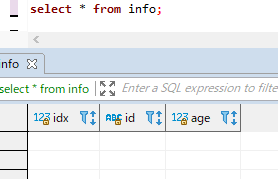
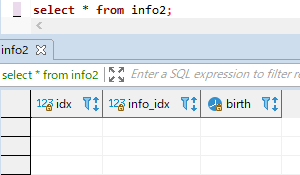
해당 데이터베이스를 확인해도 역시 깔끔하게 삭제가 되었습니다.
이런 cascade 설정도 마구잡이로 설정하면 안됩니다.
만약 transaction 테이블을 삭제하는데 master 테이블 데이터가 삭제가 된다던가, 잘못된 로직 코드로 중요한 데이터가 연쇄적으로 삭제되면 안됩니다.
물론 삭제 뿐아니라 수정, 추가도 되면 안됩니다.
| 타입 | 설명 |
|---|---|
| CascadeType.PERSIST | Entity가 추가 될 때, 연관된 Entity도 추가합니다. |
| CascadeType.MERGE | Entity가 수정 될 때, 연관된 Entity도 수정한다. |
| CascadeType.REFRESH | Entity를 새로 고칠 때, 연관된 entity도 재갱신합니다. |
| CascadeType.REMOVE | Entity를 삭제할 때, 연관된 Entity도 삭제됩니다. |
| CascadeType.DETACH | 부모 Entity가 detach()를 수행하게 되면, 연관된 Entity도 detach() 상태가 되어 변경사항이 반영되지 않습니다. |
| CascadeType.ALL | 모든 Cascade 적용 |
여기서 나오는 cascade 옵션은 EntityManager의 클래스의 함수와 관계가 있습니다.
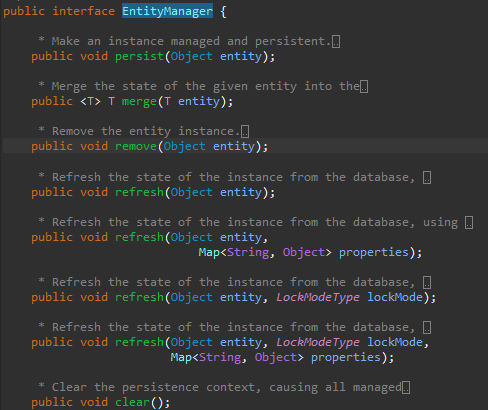
즉, 각 Entity 클래스 인스턴스를 어느 함수에서 사용하여 추가, 삭제, 수정할 때, 하위 클래스에 영향이 가는 것입니다.
fetch 옵션과 cascade 옵션은 상황에 따라 설정을 하지 않아도 ORM을 운영하는데는 크게 문제가 없습니다. 그러나 성능에는 크게 차이가 나겠네요.
그리고 코드를 작성하고 후에 테이블이 바뀐 후에 유지 보수하는 데도 큰 차이를 보입니다.
여기까지 JPA의 Entity 클래스의 레퍼런스 설정(cascade, fetch)에 대한 글이었습니다.
궁금한 점이나 잘못된 점이 있으면 댓글 부탁드립니다.