안녕하세요. 명월입니다.
이 글은 Hashmap 자료구조에 대한 글입니다.
제가 자료구조와 알고리즘을 해야지해야지 하면서 생각하면서 처음 올리는 글이 되었네요.. 사실 프로그램에서 자료구조와 알고리즘은 굉장히 중요하지만 웬만한 언어에서는 이미 구현이 되어있기 때문에 잘 신경을 쓰지 않는 부분이기도 하네요. 자료구조와 알고리즘은 사실 보통 Stack부터 Queue, Cache 순으로 가는 게 맞습니다만.. 우연히 김포프님 동영상 보다가 Hashtable 알고리즘 못 짜면 개발자도 아니다라고 약간 어그로 식으로 이야기하시길래 처음엔 후훗하면서 그 정도쯤이야 생각하다가 막상 하려니깐 어엇이라고 생각이 되어서 아, 이거 정리해 놔야겠다 싶어서 글을 작성했습니다.
먼저, Hashmap에 대해서 설명을 해야겠네요.
가장 많이 쓰는 자료구조와 알고리즘에서 배열(Array)과 연결리스트(LinkedList)가 있습니다.

위 그림에서 위는 배열로 데이터가 들어가 있는 것이고 아래는 연결리스트로 데이터를 넣는 것입니다.
여기서 우리가 앞에서 3번째의 데이터를 가져올때는 배열[2] 이런 식으로 가져올 것입니다. 그리고 연결리스트는 포인터의 탐색으로 두번 이동한 다음에 취득하겠네요.
그런데 여기서 우리는 값을 취득할 때 숫자가 아닌 키를 통해 취득하고 싶습니다.
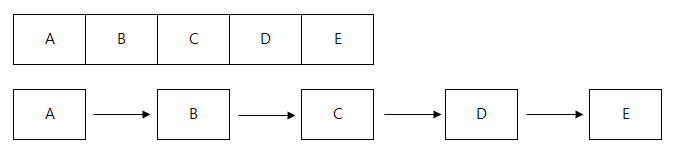
즉, 배열[A] 이렇게 가져오고 싶은 것입니다. 그런데 배열은 불가능하죠. 배열은 위치를 숫자로 표현할 수 밖에 없으니깐.
그러나 연결리스트는 가능합니다. 즉, 연결리스트는 포인터로 줄줄히 연결이 되어있고 탐색을 하면서 Key라는 키값을 넣어서 리스트->get("A") 이런 식으로 가져올 수 있겠죠.
그런데 문제가 무엇일까요? 만약 연결리스트에 값이 1000개 10000개라고 했을 때, 키와 같은 값을 찾으려면 포인터 탐색을 엄청나게 해야겠네요. 즉 가능은 한데.. 엄청나게 느려지겠네요..
그럼 배열의 탐색 속도와 연결리스트의 Key 탐색 기능을 합쳐서 만들 수 있는 방법은 없을까 했을 때, 그것을 합친 기능이 Hashmap, Hashtable입니다.

즉, 내가 Y라는 Key라는 데이터를 가져오려면 5번째 배열에서 연결리스트로 탐색을 하게 되면. 일반 연결리스트라면 25번의 탐색을 해야하는 것을 4번의 탐색으로 가져오는 것입니다.
그렇다면 Key로 가져오는건 아는데 배열의 순서는 어떻게 정하는 것일까라고 생각할 때 이게 바로 hash입니다.
hash라는 것은 프로그램 내부의에서 규칙을 정해서 Object나 String 값을 특정 수로 변환하는 것입니다. 위 그림이라면 대문자 A가 아스키코드로 97를 Key>=97 && Key<=100의 경우라면 0, Key>=101 && Key<=104는 1 이런 식으로 설정한 것이겠네요.
다시 정리하면 Hashmap이란 우리가 키를 통해서 데이터를 가져오게 할 수 있는 방식. 그래서 연결리스트를 응용했지만 연결리스트의 탐색 기능이 너무 느리다 보니 배열(Array)의 탐색을 넣어서 속도를 비약적으로 향상시킨 자료구조라고 할 수 있습니다.
#include <iostream>
// 해쉬맵의 배열 개수
#define TABLE_SIZE 10
using namespace std;
// hash 구조체 key가 int형인데.. hashmap의 배열의 최대 개수별로 나누어 나머지로 처리한다.
// 즉, 키가 0이라면 0번째 배열의 연결리스트, 10이라면 0번째 배열의 연결리스트, 11이라면 1번째 배열의 연결리스트
struct KeyHash {
// 연산자 함수형식의 재정의
unsigned long operator()(const int key) const
{
// key를 10으로 나눈 나머지
return key % TABLE_SIZE;
}
};
// 템플릿 설정
template <typename K, typename V, typename F = KeyHash>
class HashMap { // HashMap 클래스
private:
// 연결리스트를 위한 Node 클래스
class Node {
public:
// Key 값
K key;
// Value 값
V value;
// 연결리스트의 포인터
Node* next;
// 생성자 처리
Node(const K& key, const V& value) :
key(key), value(value), next(NULL) {
}
};
// 해쉬맵 배열
Node** table;
// hash 함수
F hashFunc;
public:
// 생성자
HashMap() {
// 배열 선언
table = new Node * [TABLE_SIZE]();
}
// 소멸자
~HashMap() {
// 배열 안의 연결리스트를 반복문으로 취득
for (int i = 0; i < TABLE_SIZE; ++i) {
// 연결 리스트 취득
Node* entry = table[i];
// null이 아니면
while (entry != NULL) {
// 연결리스트 가져오기
Node* prev = entry;
// 다음 연결리스트로 연결
entry = entry->next;
// 메모리 해제
delete prev;
}
// 해당 배열을 제거
table[i] = NULL;
}
// 배열 메모리 해제
delete[] table;
}
// key를 통해 데이터 취득
V get(const K& key) {
// 해쉬 함수를 통해 해쉬값 취득
unsigned long hashValue = hashFunc(key);
// 해쉬값을 통해서 연결리스트 취득
Node* entry = table[hashValue];
// 연결리스트 NULL이 발생할때까지
while (entry != NULL) {
// key가 같다면
if (entry->key == key) {
// 값을 리턴
return entry->value;
}
// key가 다르다면 다음 연결리스트로 연결
entry = entry->next;
}
}
// key를 통해 데이터를 입력
void put(const K& key, const V& value) {
// 해쉬 함수를 통해 해쉬값 취득
unsigned long hashValue = hashFunc(key);
// 포인터 변수 생성
Node* prev = NULL;
// 배열에서 연결리스트를 취득
Node* entry = table[hashValue];
// 연결리스트로 같은 키를 찾던가 끝까지 가던가
while (entry != NULL && entry->key != key) {
// 전 포인터 설정
prev = entry;
// 포인터 이동
entry = entry->next;
}
// 연결리스트 끝이라면..
if (entry == NULL) {
// Node 클래스 생성
entry = new Node(key, value);
// 이전 포인터가 없으면
if (prev == NULL) {
// 배열의 가장 앞부분
table[hashValue] = entry;
}
else {
// 연결리스트 연결하기
prev->next = entry;
}
}
// 같은 키라면
else {
// 값을 넣기
entry->value = value;
}
}
// key를 통해 데이터를 삭제
void remove(const K& key) {
// 해쉬 함수를 통해 해쉬값 취득
unsigned long hashValue = hashFunc(key);
// 포인터 변수 생성
Node* prev = NULL;
// 배열에서 연결리스트를 취득
Node* entry = table[hashValue];
// 연결리스트로 같은 키를 찾던가 끝까지 가던가
while (entry != NULL && entry->key != key) {
// 전 포인터 설정
prev = entry;
// 포인터 이동
entry = entry->next;
}
// 연결리스트 끝이라면..
if (entry == NULL) {
// 삭제할 것이 없네...
return;
}
else {
// 가장 앞의 포인터라면
if (prev == NULL) {
// 연결리스트의 맨 앞을 연결
table[hashValue] = entry->next;
}
else {
// 연결리스트에서 앞과 다음 포인터를 연결
prev->next = entry->next;
}
// 메모리 해제
delete entry;
}
}
};
// String hash코드
struct StringKeyHash {
// 연산자 함수형식의 재정의
unsigned long operator()(const string& key) const
{
// 변수 초기
int hashValue = -1;
int tmp = 0;
// String를 char로 분해해서 아스키코드를 다 더함
for (char c : key) {
tmp += (int)c;
}
// 해쉬값 만들기
hashValue = tmp % TABLE_SIZE;
// 리턴
return hashValue;
}
};
// 실행 함수
int main()
{
// key가 int형의 hashmap
HashMap<int, string> hashmap1;
// key가 string형의 hashmap
HashMap<string, int, StringKeyHash> hashmap2;
// 키가 int형식의 값 넣기
hashmap1.put(1, "abc");
hashmap1.put(2, "bcd");
hashmap1.put(3, "ttt");
hashmap1.put(4, "aaa");
// 키가 string형식의 값 넣기
hashmap2.put("abc", 1);
hashmap2.put("bcd", 2);
hashmap2.put("ttt", 3);
hashmap2.put("aaa", 4);
// 키가 int형식의 값 출력
cout << hashmap1.get(1) << endl;
cout << hashmap1.get(2) << endl;
cout << hashmap1.get(3) << endl;
cout << hashmap1.get(4) << endl;
// 키가 string형식의 값 출력
cout << hashmap2.get("abc") << endl;
cout << hashmap2.get("bcd") << endl;
cout << hashmap2.get("ttt") << endl;
cout << hashmap2.get("aaa") << endl;
}

Java의 경우는 클래스 형식의 데이터는 hashCode() 함수를 제공합니다. hashCode함수는 클래스가 Stack - heap 구조의 경우이기 때문에 메모리 주소가 반드시 있고 그것을 int형으로 리턴한 것입니다. (String은 hashCode를 재정의 했기 때문에 문자의 값을 hashCode로 출력합니다.)

// 해쉬 맵 클래스
class HashMap<K, V> {
// 연결리스트의 노드 인라인 클래스
class Node<K, V> {
// key 값
public K key;
// value 값
public V value;
// 연결리스트 다음 포인터
public Node<K, V> next = null;
// 생성자
public Node(K key, V value) {
this.key = key;
this.value = value;
}
}
// hashmap의 배열 크기
private final int TABLE_SIZE = 10;
// hashmap의 배열
private final Node<K, V>[] table;
// 생성자
public HashMap() {
// hashmap의 배열 인스턴스 생성
this.table = new Node[TABLE_SIZE];
}
// key로 value값 취득 함수
public V get(K key) {
// hashCode를 통해 hash값 변환
int hash = key.hashCode() % TABLE_SIZE;
// 연결리스트 취득
Node<K, V> entry = table[hash];
// 연결리스트 끝까지
while (entry != null) {
// key 값이 같으면
if (entry.key.equals(key)) {
// value 리턴
return entry.value;
}
// 다음 연결리스트로
entry = entry.next;
}
// 없으면 null
return null;
}
// key를 통해 데이터를 입력
public void put(K key, V value) {
// hashCode를 통해 hash값 변환
int hash = key.hashCode() % TABLE_SIZE;
// 포인터 변수 생성
Node<K, V> prev = null;
// 배열에서 연결리스트를 취득
Node<K, V> entry = table[hash];
// 연결리스트로 같은 키를 찾던가 끝까지 가던가
while (entry != null && !entry.key.equals(key)) {
// 전 포인터 설정
prev = entry;
// 포인터 이동
entry = entry.next;
}
// 연결리스트 끝이라면..
if (entry == null) {
// 인스턴스 생성
entry = new Node<K, V>(key, value);
// 이전이 없다면
if (prev == null) {
// hashmap의 배열에 연결
table[hash] = entry;
} else {
// 연결리스트 다음에 연결
prev.next = entry;
}
} else {
// Node의 값 변경
entry.value = value;
}
}
// key를 통해 데이터를 삭제
public void remove(K key) {
// hashCode를 통해 hash값 변환
int hash = key.hashCode() % TABLE_SIZE;
// 포인터 변수 생성
Node<K, V> prev = null;
// 배열에서 연결리스트를 취득
Node<K, V> entry = table[hash];
// 연결리스트로 같은 키를 찾던가 끝까지 가던가
while (entry != null && !entry.key.equals(key)) {
// 전 포인터 설정
prev = entry;
// 포인터 이동
entry = entry.next;
}
// 연결리스트 끝이라면..
if (entry == null) {
// 값이 없네?
return;
} else {
// 연결리스트의 가장 맨 앞이라면
if (prev == null) {
// 배열의 앞부분을 재연결
table[hash] = entry.next;
} else {
// 앞의 연결리스트와 다음 연결리스트를 연결
prev.next = entry.next;
}
}
}
}
// 실행 클래스
public class Program {
// 실행 함수
public static void main(String[] args) {
// key가 int형의 hashmap
HashMap<Integer, String> hashmap1 = new HashMap<>();
// key가 string형의 hashmap
HashMap<String, Integer> hashmap2 = new HashMap<>();
// 키가 int형식의 값 넣기
hashmap1.put(1, "abc");
hashmap1.put(2, "bcd");
hashmap1.put(3, "ttt");
hashmap1.put(4, "aaa");
// 키가 string형식의 값 넣기
hashmap2.put("abc", 1);
hashmap2.put("bcd", 2);
hashmap2.put("ttt", 3);
hashmap2.put("aaa", 4);
// 키가 int형식의 값 출력
System.out.println(hashmap1.get(1));
System.out.println(hashmap1.get(2));
System.out.println(hashmap1.get(3));
System.out.println(hashmap1.get(4));
// 키가 string형식의 값 출력
System.out.println(hashmap2.get("abc"));
System.out.println(hashmap2.get("bcd"));
System.out.println(hashmap2.get("ttt"));
System.out.println(hashmap2.get("aaa"));
}
}

Java와 C#은 구조가 비슷하기 때문에 비슷한 코드가 나오지 않을까 싶네요.
using System;
using System.Globalization;
namespace Blog
{
// 해쉬 맵 클래스
class HashMap<K, V>
{
// 연결리스트의 노드 인라인 클래스
class Node
{
// key 값
public K key;
// value 값
public V value;
// 연결리스트 다음 포인터
public Node next = null;
// 생성자
public Node(K key, V value)
{
this.key = key;
this.value = value;
}
}
// hashmap의 배열 크기
private const int TABLE_SIZE = 10;
// hashmap의 배열
private Node[] table;
// 생성자
public HashMap()
{
// hashmap의 배열 인스턴스 생성
this.table = new Node[TABLE_SIZE];
}
// key로 value값 취득 함수
public V get(K key)
{
// hashCode를 통해 hash값 변환
int hash = Math.Abs(key.GetHashCode() % TABLE_SIZE);
// 연결리스트 취득
Node entry = table[hash];
// 연결리스트 끝까지
while (entry != null)
{
// key 값이 같으면
if (entry.key.Equals(key))
{
// value 리턴
return entry.value;
}
// 다음 연결리스트로
entry = entry.next;
}
// 없으면 null
return default(V);
}
// key를 통해 데이터를 입력
public void put(K key, V value)
{
// hashCode를 통해 hash값 변환
int hash = Math.Abs(key.GetHashCode() % TABLE_SIZE);
// 포인터 변수 생성
Node prev = null;
// 배열에서 연결리스트를 취득
Node entry = table[hash];
// 연결리스트로 같은 키를 찾던가 끝까지 가던가
while (entry != null && !entry.key.Equals(key))
{
// 전 포인터 설정
prev = entry;
// 포인터 이동
entry = entry.next;
}
// 연결리스트 끝이라면..
if (entry == null)
{
// 인스턴스 생성
entry = new Node(key, value);
// 이전이 없다면
if (prev == null)
{
// hashmap의 배열에 연결
table[hash] = entry;
}
else
{
// 연결리스트 다음에 연결
prev.next = entry;
}
}
else
{
// Node의 값 변경
entry.value = value;
}
}
// key를 통해 데이터를 삭제
public void remove(K key)
{
// hashCode를 통해 hash값 변환
int hash = Math.Abs(key.GetHashCode() % TABLE_SIZE);
// 포인터 변수 생성
Node prev = null;
// 배열에서 연결리스트를 취득
Node entry = table[hash];
// 연결리스트로 같은 키를 찾던가 끝까지 가던가
while (entry != null && !entry.key.Equals(key))
{
// 전 포인터 설정
prev = entry;
// 포인터 이동
entry = entry.next;
}
// 연결리스트 끝이라면..
if (entry == null)
{
// 값이 없네?
return;
}
else
{
// 연결리스트의 가장 맨 앞이라면
if (prev == null)
{
// 배열의 앞부분을 재연결
table[hash] = entry.next;
}
else
{
// 앞의 연결리스트와 다음 연결리스트를 연결
prev.next = entry.next;
}
}
}
}
internal class Program
{
static void Main(string[] args)
{
// key가 int형의 hashmap
HashMap<int, String> hashmap1 = new HashMap<int, String>();
// key가 string형의 hashmap
HashMap<String, int> hashmap2 = new HashMap<String, int>();
// 키가 int형식의 값 넣기
hashmap1.put(1, "abc");
hashmap1.put(2, "bcd");
hashmap1.put(3, "ttt");
hashmap1.put(4, "aaa");
// 키가 string형식의 값 넣기
hashmap2.put("abc", 1);
hashmap2.put("bcd", 2);
hashmap2.put("ttt", 3);
hashmap2.put("aaa", 4);
// 키가 int형식의 값 출력
Console.WriteLine(hashmap1.get(1));
Console.WriteLine(hashmap1.get(2));
Console.WriteLine(hashmap1.get(3));
Console.WriteLine(hashmap1.get(4));
// 키가 string형식의 값 출력
Console.WriteLine(hashmap2.get("abc"));
Console.WriteLine(hashmap2.get("bcd"));
Console.WriteLine(hashmap2.get("ttt"));
Console.WriteLine(hashmap2.get("aaa"));
Console.WriteLine("Press any key...");
Console.ReadKey();
}
}
}

여기까지 Hashmap 자료구조에 대한 글이었습니다.
궁금한 점이나 잘못된 점이 있으면 댓글 부탁드립니다.