안녕하세요. 명월입니다.
이 글은 C#의 Linq 쿼리식을 사용하는 방법에 대한 글입니다.
이전에 Linq식에 대해서 간략하게 설명한 적이 있습니다.
링크 - [C#] 27. 리스트(List)와 딕셔너리(Dictionary), 그리고 Linq식 사용법
다시 간단하게 설명하면 Linq은 프로그램 상에서 설정된 객체의 집합, 즉 리스트(List)나 딕셔너리(Dictionary)에 설정된 데이터를 효과적으로 분류 및 검색을 하기 위한 C# 프로그램 문법입니다.
Linq의 방법은 쿼리식과 함수식이 있는데, 그 중 쿼리식은 데이터 베이스에서 사용하는 SQL 쿼리식과 비슷한 방법입니다.
가장 기본적으로 사용하는 방법은 from in where select입니다.
using System;
using System.Collections.Generic;
using System.Linq;
namespace Example
{
// 예제 클래스
class Node
{
// 값을 생성자로만 입력한다.
public Node(int data)
{
// 프로퍼티 Data에 값을 입력
this.Data = data;
}
// Data 프로퍼티
public int Data
{
// 입력은 생성자로만 받는다.
get; private set;
}
}
class Program
{
// 실행 함수
static void Main(string[] args)
{
// 리스트 선언(리스트의 객체는 Node 클래스)
var list = new List<Node>();
// i가 0부터 9까지
for (int i = 0; i < 10; i++)
{
// 리스트에 데이터를 삽입
list.Add(new Node(i));
}
// Node 클래스의 Data 값이 5 초과된 인스턴스를 List<int> 형식으로 분류한다.
var filterList = from node in list where node.Data > 5 select node.Data;
// 필터된 리스트를 반복문으로 추출
foreach (var node in filterList)
{
// 콘솔 출력
Console.WriteLine(node);
}
// 아무 키나 누르시면 종료합니다.
Console.WriteLine("Press any key...");
Console.ReadLine();
}
}
}
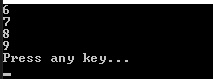
먼저 from in에 대해서 설명하면 in 뒤에 변수는 보통 검색하고자 하는 리스트의 변수입니다.
그리고 foreach 반복문처럼 하나의 객체로 치환하는 것이 from 뒤에 있는 변수 입니다.
즉, foreach(Node node in list)가 from node in list와 같은 뜻입니다.
where은 반복문 안의 조건을 만드는 것으로 node.Data > 5는 if(node.Data > 5)와 같은 의미입니다.
select는 return 된 결과에 따른 최종 filterList의 자료형이 결정되는 것입니다만, select node를 했으면 IEnumerable<Node> 타입이 되겠지만, 위에서는 node.Data를 했기 때문에 IEnumerable<int> 타입으로 리턴됩니다.
여기서 참고로 IEnumerable의 인터페이스는 List의 상위 인터페이스입니다.

List처럼 사용할 수 있는 인터페이스입니다만, 정확하게는 반복자 패턴(iterator pattern)의 인터페이스입니다.
즉, List와 비슷하지만 Add나 Remove처럼 데이터를 추가 삭제를 하지 못하고 foreach로 데이터를 가져오는 것 밖에 할 수 없습니다.
참조 - [Design pattern] 반복자 패턴 (Iterator pattern)
참고로 그럼 Linq으로 나온 결과에 데이터를 추가, 삭제를 하기 위해서는 ToList() 함수로 형변환을 하고 List처럼 사용하면 됩니다.
using System;
using System.Collections.Generic;
using System.Linq;
namespace Example
{
// 예제 클래스
class Node
{
// 값을 생성자로만 입력한다.
public Node(int data)
{
// 프로퍼티 Data에 값을 입력
this.Data = data;
}
// Data 프로퍼티
public int Data
{
// 입력은 생성자로만 받는다.
get; private set;
}
}
class Program
{
// 실행 함수
static void Main(string[] args)
{
// 리스트 선언(리스트의 객체는 Node 클래스)
var list = new List<Node>();
// i가 0부터 9까지
for (int i = 0; i < 10; i++)
{
// 리스트에 데이터를 삽입
list.Add(new Node(i));
}
// Node 클래스의 Data 값이 5 초과된 인스턴스를 List<int> 형식으로 분류한다.
var filterList = from node in list where node.Data > 5 select node.Data;
// 위 쿼리식의 결과 IEnumerable 타입에서 List 타입으로 변경
var newList = filterList.ToList();
// select node.Data로 인해 List<int> 타입으로 설정하였기 때문에, Node 인스턴스를 넣는 것이 아님
newList.Add(1);
// 새로운 리스트를 반복문으로 추출
foreach (var node in newList)
{
// 콘솔 출력
Console.WriteLine(node);
}
// 아무 키나 누르시면 종료합니다.
Console.WriteLine("Press any key...");
Console.ReadLine();
}
}
}

다시 쿼리식으로 돌아와서 실무 프로그램을 하다보면 사실 from where select가 가장 많이 사용됩니다.
그 외에는 orderby가 있고 join, let을 많이 사용합니다.
orderby은 데이터의 정렬를 하는 식이고, join은 두가지 리스트를 합치는 식입니다.
using System;
using System.Collections.Generic;
using System.Linq;
namespace Example
{
// 예제 클래스
class Node
{
// 값을 생성자로만 입력한다.
public Node(int key, string value)
{
// 프로퍼티에 값을 입력
this.Key = key;
this.Value = value;
}
// Key 프로퍼티
public int Key
{
// 입력은 생성자로만 받는다.
get; private set;
}
// Value 프로퍼티
public string Value
{
// 입력은 생성자로만 받는다.
get; private set;
}
}
class Program
{
// 실행 함수
static void Main(string[] args)
{
// 리스트 선언(리스트의 객체는 Node 클래스)
var list1 = new List<Node>();
var list2 = new List<Node>();
// i가 0부터 9까지
for (int i = 0; i < 10; i++)
{
// 리스트에 데이터를 삽입
list1.Add(new Node(i, "List1:" + i));
list2.Add(new Node(i, "List2:" + i));
}
// list1의 기본 테이블과 list2의 5 초과된 결과 값의 node2로 치환하고 Key로 매핑을 하고 결과를 node3으로 내보낸다.
// node1의 키로 내림차순으로 전환하고
// 결과를 다시 Node 인스턴스를 생성해서 IEnumerable로 리턴한다.
// value의 값은 node3에 미핑되지 않는 값, 즉, 0부터 5까지의 값이 없기 때문에 빈 string으로 넣고 그 외에는 node3의 value 값을 넣는다.
var filterList = from node1 in list1
join node2 in (from sub in list2 where sub.Key > 5 select sub) on node1.Key equals node2.Key into node3
orderby node1.Key descending
select new Node(node1.Key, node3.ToArray().Length > 0 ? node3.ToArray()[0].Value : "");
// 필터된 리스트를 반복문으로 추출
foreach (var item in filterList)
{
// 콘솔 출력
Console.WriteLine("Key - " + item.Key + " Value - " + item.Value);
}
// 아무 키나 누르시면 종료합니다.
Console.WriteLine("Press any key...");
Console.ReadLine();
}
}
}
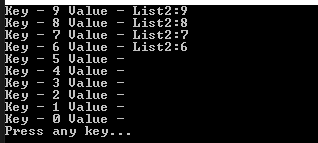
Linq 식의 Join은 데이터 베이스의 outer join과 비슷합니다.
즉, 최초의 list1를 기준으로 list2를 join을 한 결과를 into로 node3으로 만듭니다. 즉, join되는 값이 없으면 0개의 IEnumerable 데이터로, 있으면 1개의 IEnumerable 데이터로 node3으로 치환됩니다.
그리고 순서를 orderby를 통해서 list1기준의 내림차순으로 만듭니다.
그 결과를 select 에서 새로운 Node 인스턴스로 재생성합니다.
콘설 결과를 보니 내림차순으로 나오고 0부터 5까지의 데이터는 역시 매핑되는 값이 없으니 공백 string으로 출력이 되네요.
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
namespace Example
{
// 예제 클래스
class Node
{
// 값을 생성자로만 입력한다.
public Node(int key, string value)
{
// 프로퍼티에 값을 입력
this.Key = key;
this.Value = value;
}
// Key 프로퍼티
public int Key
{
// 입력은 생성자로만 받는다.
get; private set;
}
// Value 프로퍼티
public string Value
{
// 입력은 생성자로만 받는다.
get; private set;
}
// 클래스의 String을 리턴
public override string ToString()
{
return "Key - " + Key + " Value - " + Value;
}
}
// Group 된 클래스
class Group
{
// 값을 생성자로만 입력한다.
public Group(int key, IEnumerable<Node> value)
{
// 프로퍼티에 값을 입력
this.Key = key;
this.Value = value;
}
// Key 프로퍼티
public int Key
{
// 입력은 생성자로만 받는다.
get; private set;
}
// Value 프로퍼티
public IEnumerable<Node> Value
{
// 입력은 생성자로만 받는다.
get; private set;
}
// 클래스의 String을 리턴
public override string ToString()
{
// 그룹으로 된 value 데이트의 String 값을 모음
var sb = new StringBuilder();
foreach (var item in Value)
{
sb.AppendLine(item.ToString());
}
return sb.ToString();
}
}
class Program
{
// 실행 함수
static void Main(string[] args)
{
// 리스트 선언(리스트의 객체는 Node 클래스)
var list = new List<Node>();
// i가 0부터 9까지
for (int i = 0; i < 10; i++)
{
// 리스트에 데이터를 삽입
list.Add(new Node(i, "List:" + i));
}
// 짝수, 홀수 별로 그룹을 나누고 그 키로 Node를 재정렬한다.
var filerList = from node in list group node by node.Key % 2 into g select new Group(g.Key, g);
// filerList의 키 순서대로 반복문
foreach (var item in filerList)
{
// 콘솔 출력
Console.WriteLine("Group Key - " + item.Key);
Console.WriteLine(item.ToString());
}
// 아무 키나 누르시면 종료합니다.
Console.WriteLine("Press any key...");
Console.ReadLine();
}
}
}
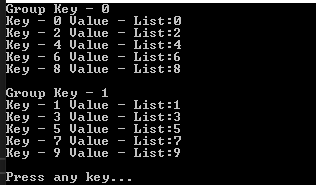
위 예제는 리스트를 그룹화 했습니다.
먼저 group은 그룹화할 대상을 설정하고 by로 인해 키를 설정합니다. node.Key % 2로 모든 리스트로 나올 수 있는 경우의 수는 0과 1입니다.
즉, 0과 1의 리스트를 만들어서 0이 되는 값의 list와 1이 되는 값의 리스트를 만들었습니다. 그의 결과를 Group이라는 클래스의 인스턴스를 생성해서 다시 0과 1의 IEnumerable타입으로 생성합니다.
결과를 보면 0과 1로 그룹이 된 것을 확인할 수 있습니다.
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
namespace Example
{
// 예제 클래스
class Node
{
// 값을 생성자로만 입력한다.
public Node(int data)
{
// 프로퍼티에 값을 입력
this.Data = data;
}
// Data 프로퍼티
public int Data
{
// 입력은 생성자로만 받는다.
get; private set;
}
}
class Program
{
// 실행 함수
static void Main(string[] args)
{
// 리스트 선언(리스트의 객체는 Node 클래스)
var list = new List<Node>();
// i가 0부터 9까지
for (int i = 0; i < 10; i++)
{
// 리스트에 데이터를 삽입
list.Add(new Node(i));
}
// let은 변수의 재정의입니다.
var filerList = from node in list let data = node.Data * 100 select new Node(data);
// filerList의 키 순서대로 반복문
foreach (var item in filerList)
{
// 콘솔 출력
Console.WriteLine(item.Data);
}
// 아무 키나 누르시면 종료합니다.
Console.WriteLine("Press any key...");
Console.ReadLine();
}
}
}
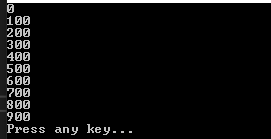
위에 쿼리식에서는 let을 사용했습니다.
let의 키워드는 데이터를 재정의하는 식입니다. 즉, from node in list로 재정의된 node의 Node 클래스의 인스턴스를 let을 통해 node.Data의 값에 100을 곱해서 int값으로 재치환합니다.
그것을 다시 select를 통해서 Node 클래스의 인스턴스를 생성해서 리스트로 만듭니다.
결과는 node.Data가 100이 곱해져서 다시 Node의 인스턴스 리스트로 나온 것을 확인할 수 있습니다.
Linq의 쿼리식은 MS의 .net framework Doc에서 설명하고 있으니 참조하시면 됩니다.
링크 - https://docs.microsoft.com
Linq 쿼리식을 잘 활용하면 프로그램을 작성할 때, 많은 소스를 줄일 수 있고 검증된 쿼리식이기 때문에 사용자가 작성한 알고리즘보다는 뛰어난 성능으로 사용할 수 있습니다.
물론 그것이 쿼리를 제대로 사용했을 경우입니다. 불필요한 join과 from, let으로 인한 데이터 조인과 치환, 그리고 잘못된 where이 오히려 성능을 떨어트릴 수 있습니다.
그리고 또 쿼리식은 보통의 프로그램 코드식이 아니라서 너무 자주 사용하는 경우, 반대로 소스의 가독성이 매우 않 좋아 질 수 있습니다. 그리고 리스트의 필터와 조인, 치환 상태의 디버그를 확인할 수 없기 때문에 개발하는 데 불편한 점이 많이 있습니다.
그래서 오히려 실무에서는 Linq의 쿼리식 보다는 함수식을 많이 사용합니다.
여기까지 C#의 Linq 쿼리식을 사용하는 방법에 대한 글이었습니다.
궁금한 점이나 잘못된 점이 있으면 댓글 부탁드립니다.
'Study > C#' 카테고리의 다른 글
| [C#] 32. 익명 형식(Anonymous Types) 사용법 (0) | 2021.09.20 |
|---|---|
| [C#] 31. 어트리뷰트(Attribute)를 사용하는 방법 (2) | 2021.09.17 |
| [C#] 30. 제네릭(Generic) 사용법 (0) | 2021.09.16 |
| [C#] 29. Linq 함수식을 사용하는 방법 (0) | 2021.09.15 |
| [C#] 27. 리스트(List)와 딕셔너리(Dictionary), 그리고 Linq식 사용법 (0) | 2021.09.13 |
| [C#] 26. var 키워드와 dynamic 키워드 (0) | 2021.09.10 |
| [C#] 25. 예외 처리(try ~ catch)하는 방법 (0) | 2021.09.09 |
| [C#] 24. 이벤트(event) 키워드 사용법 (0) | 2021.09.08 |